分表后需要注意的二三事 | crossoverJie's Blog
- 安宇雨 - 随手采集
- 2019-08-22 09:48:16
- 随手采集
- 0000-未整理-等待研究

[](#%E5%89%8D%E8%A8%80 "前言")前言
本篇是上一篇《一次分表踩坑实践的探讨》,所以还没看过的朋友建议先看上文。
还是先来简单回顾下上次提到了哪些内容:
- 分表策略:哈希、时间归档等。
- 分表字段的选择。
- 数据迁移方案。
而本篇文章的背景是在我们上线这段时间遇到的一些问题并尝试解决的方案。
[](#%E9%97%AE%E9%A2%98%E4%BA%A7%E7%94%9F "问题产生")问题产生
之前提到在分表应用上线前我们需要将原有表的数据迁移到新表中,这样才能保证业务不受影响。
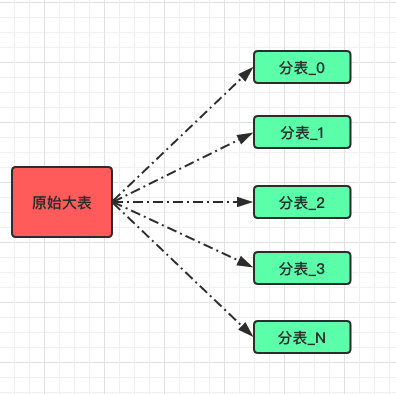
所以我们单独写了一个迁移应用,它负责将大表中的数据迁移到 64 张分表,而再迁移过程中产生的数据毕竟是少数,最后在上线当晚再次迁移过去即可。
一切想的很美好,当这个应用上线后却发现没这么简单。
[](#%E6%95%B0%E6%8D%AE%E5%BA%93%E8%B4%9F%E8%BD%BD%E5%8D%87%E9%AB%98 "数据库负载升高")数据库负载升高
首先第一个问题是数据库自己就顶不住了,在我们上这个迁移程序之前数据库的压力本身就比较大,这个应用一上去就成了最后一根稻草。
最后导致的结果是:所有连接了数据库的程序大部分的操作都出现超时,获取不到数据库连接等一系列的异常。
最后没办法我们只能把这个应用放到凌晨执行,但其实后面观察发现依然不行。
虽说凌晨的业务量下降,但依然有少部分的请求过来,也会出现各种数据库异常。
再一个是迁移程序的效率也非常低下,按照这样是速度,我们预估了一下迁移时间,大约需要 10 几天才能把三张最大的表(3、4亿的数据)迁移到分表中。
于是我们换了一个方案,将这个迁移程序在从库中运行,最后再用运维的方法将分表直接导入进主库。
因为从库的压力要比主库小很多,对业务的影响很小,同时迁移的效率也要快很多。
即便是这样也花了一晚上+一个白天的时间才将一张 1亿的数据迁移完成,但是业务上的压力越来越大,数据量再不断新增,这个效率依然不够。
[](#%E5%85%BC%E5%AE%B9%E6%96%B9%E6%A1%88 "兼容方案")兼容方案
最终没办法只有想一个不迁移数据的方案,但是新产生的数据还是往分表里写,至少保证大表的数据不再新增。
但这样对于以前的数据咋办呢?总不能不让看了吧。
其实对于数据的操作无非就分为增删改查,就这四种操作来看看如何兼容。
[](#%E6%96%B0%E5%A2%9E "新增")新增
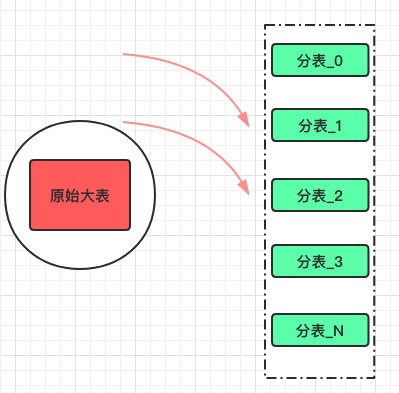
新增最简单,所有的数据根据分表规则直接写入新表,这样可以保证老表的数据不再新增。
[](#%E5%88%A0%E9%99%A4 "删除")删除
删除就要比新增稍微复杂一些,比如用户想要删除他个人产生的一条信息(比如说是订单数据),有可能这个数据在新表也可能在老表。
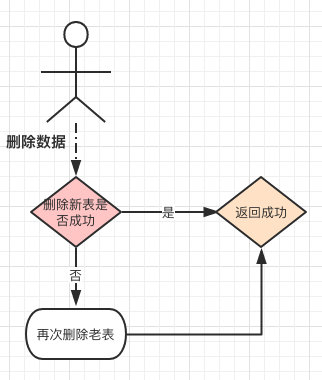
所以删除时优先删除新表(毕竟新产生的数据访问的频次越高),如果删除失败再从老表删除一次。
[](#%E4%BF%AE%E6%94%B9 "修改")修改
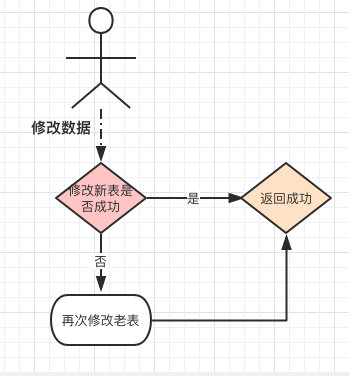
而修改同理,同样的会不确定数据存在于哪里,所以先要修改新表,失败后再次修改老表。
[](#%E6%9F%A5%E8%AF%A2 "查询")查询
查询相对就要复杂一些了,因为这些大表的数据大部分都是存放一个用户产生的多条记录(比如一个用户的订单信息)。
这时在页面上通常都会有分页,并且按照时间进行排序。
麻烦的地方就出在这里:既然是要分页那就有可能出现要查询一部分分表数据和原来的大表数据做组合。
所以这里的查询其实分为三种情况。
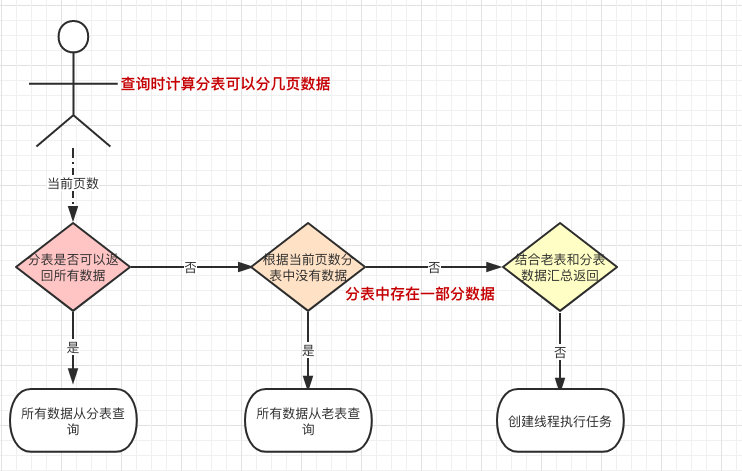
- 首先查询的时候要计算这个用户所在分表中的数据可以分为几页。
- 第一步首先判断当前页是否可以在分表中全部获取,如果可以则直接从分表中取出数据返回(假设分页中总共可以查询 2 页数据,当前为第 1 页,那就全部取分表数据)。
- 如果不可以就要判断当前页数在分表中是否取不到任何一条数据,如果是则直接取老表数据(比如现在要取第 5 页的数据,分表中一共才只有 2 页数据,所以第 5 页数据只能全部从老表中获取)。
- 但如果分表和老表都存在一部分数据时,则需要同时取两张表然后做一个汇总再返回。
这种逻辑只适用于根据分表字段进行查询分页的前提下
- *
我想肯定会有朋友提出这样是否会有性能问题?
同时如果在计算分表分页数量时出现并发写入的情况,导致分页数量不准从而对后续的查询出现影响该怎么处理?
首先第一个性能问题:
其实这个要看怎么取舍,为了这样的兼容目的其实会比常规查询多出几个步骤:
- 判断当前页是否可以在分表中查询。
- 当新老表中都有数据时候需要额外多查询一张大表。
第一个判断逻辑其实是在内存中计算,这个损耗我觉得完全可以忽略不计。
至于第二步确实会有损耗,毕竟多查了一张表。
但在分表之前所有的数据都是从老表中获取的,当时的业务也没有出现问题;现在多的只是查询分表而已,但分表的数据量肯定要比大表小的多,而且有索引,所以这个效率也不会慢多少。
而且根据局部性原理及用户的使用习惯来看,老表中的数据很少会去查询,随着时间的推移所有的数据肯定都会从分表中获取,逐渐老表就会成为历史表。
而第二个并发带来的问题我觉得影响也不大,一定要这个分页准的前提肯定得是加锁了,但为了这样一个不痒的小问题却带来性能的下降,我觉得是不划算的。
而且后续我们也可以慢慢的将老表的数据迁移到新表,这样就可以完全去掉这个兼容逻辑了,所有的数据都从分表中获取。
[](#%E6%80%BB%E7%BB%93 "总结")总结
还是之前那句话,这里的各种操作、方法不适合所有人,毕竟脱离场景都是耍牛氓。
比如分表搞的早,业务上允许一定的时间将数据迁移到分表那就不会有这次的兼容处理。
甚至一开始业务规划合理、团队架构师看的长远,一来就将关键数据分表存储那根本就不会有数据迁移这个流程(大厂有经验的团队可能,小公司小作坊都得靠自己摸索)。
这段期间也被数据库折腾惨了,数据库是最后一根稻草果然也不是瞎说的。
你的点赞与分享是对我最大的支持
Original url: Access
Created at: 2019-08-22 09:48:16
Category: default
Tags: none
未标明原创文章均为采集,版权归作者所有,转载无需和我联系,请注明原出处,南摩阿彌陀佛,知识,不只知道,要得到
加入组织
-
-
1. 手Q扫左侧二维码
2. 搜Q群:861085013
3. 点击


热门标签
- Laravel (35)
- Elasticsearch (20)
- PHP (25)
- Mysql (15)
- centos (46)
- vue.js (7)
- javascript (1)
- node.js (5)
- python (1)
- git (13)
- gitlab (4)
- redis (3)
- nginx (7)
- sublime-text (1)
- bootstrap (1)
- 自然语言处理 NLP (2)
- 数据挖掘 (2)
- 机器学习 (5)
- 深度学习 (3)
- composer (7)
- Java!弃! (24)
- 超位魔法-Bug (1)
- 0000-未整理-等待研究 (7919)
- 微服务架构 (2)
- 创业 (3)
- 研发管理 (3)
- 绩效考核 (3)
- 人工智能 (3)
- Robot (1)
- 高等数学 (2)
- 思想想法-Mind (4)
- oAuth (9)
- CSS (5)
- C (5)
- MacOS (16)
- ES6 (19)
- Linux (17)
- Ubuntu (4)
- Kali (2)
- nvidia (1)
- BeyondCompare - 文件比对 (4)
- VMware (3)
- 0005-亲测可用 (48)
- 救援模式 (3)
- 0003-全部整理 - 已整理 (24)
- 0004-划重点-定要细看-Review (26)
- DevOps (1)
- kafka (1)
- svn (2)
- 南摩阿彌陀佛 (2)
- 阿里云 (1)
- gogs (6)
- oneinstack (6)
- PHP-环境 (1)
- 开源项目库介绍 (1)
- 敏捷开发 (2)
- Scrum (2)
- Laravel-迁移 (2)
- 数据丢失 (1)
- 转义 (3)
- Let's Encrypt (4)
- SSL (3)
- HTTPS证书 (4)
- Certbot (1)
- maven (16)
- nexus (15)
- Spring Boot (12)
- Spring Cloud (2)
- Spring (4)
- PDMan (2)
- AppImage (2)
- Docker (21)
- MyBatis (11)
- Generator (2)
- superdesk-libs (1)
- Homebrew (6)
- 热部署 (3)
- 操作系统 (1)
- 个人标记 (2)
- IDE (11)
- idea (10)
- 开发环境-搭建 (3)
- websocket (1)
- 专题-k8s-docker-springcloud-springboot (20)
- jQuery插件 (1)
- iptables (2)
- 专题-正则表达式 (2)
- Regex (2)
- 程序猿道具 (2)
- 撸代码道具 (2)
- 专题-elasticsearch-logstash-kibana (17)
- 专题-nginx-配置静态文件访问 (3)
- http.postbuffer (3)
- git-error (3)
- 墙外 (7)
- 0001-整理部分 - 研究ing (17)
- golang (2)
- utf8mb4 (2)
- golang镜像代理 (1)
- 机械键盘 (7)
- 机械键盘-客制化 (4)
- 机械键盘-商品类 (3)
- 机械键盘-改装 (18)
- 机械键盘-客制化配件 (4)
- 超级前台时期 (10)
- question-mysql (5)
- developer-龙美珍 (2)
- 机械键盘-本人制作 (8)
- linux-输入法-Input Method (6)
- fcitx (5)
- 营销广告 (2)
- Visual Studio Code (1)
- linux-command (2)
- ftp 工具 (2)
- FileZilla (2)
- ibus (1)
- 前端视觉 (3)
- JavaScript 3D library (2)
- 机械键盘-拆解评测 (9)
- 机械键盘-知识科普 (8)
- 机械键盘-维修 (2)
- 前端技术 (3)
- html5 (2)
- SEO (2)
- Sass (1)
- logback (2)
- Java-日志-框架 (4)
- 在线工具 (6)
- 自动化测试开坑 (4)
- Jmeter (3)
- 清除 history (3)
- 编程 - 可视化-道具 (1)
- superdesk-app-transfer (1)
- superdesk-app-transfer-old2new (1)
- superdesk-app-transfer-canal (2)
- superdesk-app-transfer-canal-instance-supercloud (1)
- superdesk-app-platform (2)
- superdesk-app-services (1)
- superdesk-app-services-common (1)
- 专题-Lambda (4)
- phpMyAdmin (7)
- 微擎 (1)
- 范型 (2)
- Java 不得不学 (2)
- 切面式编程(interceptor)(拦截器?) (2)
- 事件式编程(event) (3)
- TDD式编程 (1)
- Lombok (3)
- markdown - 解析器 (2)
- centos8 - 踩点 (2)
- 超级思维 (1)
- 个人发展协会 (2)
- Shadowsocks (6)
- 专题-spring cloud 全家桶 (1)
- brew (1)
- okhttp3 (1)
- 超级前台 (1)
- superdesk-uniorder (1)
- HHKB Professional BT蓝牙 (1)
- 电商军规:打造线上赚钱旺铺 (2)
- Swagger (1)
- Freemarker (1)
- 1011-收集箱 (1)
- 1015-专题研究 (1)
- 油猴 tampermonkey (1)
- 内网穿透 (4)
- 黑苹果 (1)
- Chrome 扩展 (2)
- Chrome Extension (2)
- 游戏 (1)
- 原神 3.0 须弥 (1)
- poi v3.16 (10)
- 分布式锁 (3)
- KiCad-7 (1)
- KiCad (11)
- APITable (4)
- 机器视觉 (9)
- VisionMaster (9)
- RXTXcomm (1)
- Purejavacomm (1)
- javaxcomm (2)
- 串口-RS232-RS485-Java (4)
置顶推荐
java windows火焰图_mob64ca12ec8020的技术博客_51CTO博客 - 在windows下不可行,不知道作者是怎样搞的 监听SpringBoot 服务启动成功事件并打印信息_监听springboot启动完毕-CSDN博客 SpringBoot中就绪探针和存活探针_management.endpoint.health.probes.enabled-CSDN博客 u2u转换板 - 嘉立创EDA开源硬件平台 Spring Boot 项目的轻量级 HTTP 客户端 retrofit 框架,快来试试它!_Java精选-CSDN博客 手把手教你打造一套最牛的知识笔记管理系统! - 知乎 - 想法有重合-理论可参考 安宇雨 闲鱼 机械键盘 客制化 开贴记录 文本 linux 使用find命令查找包含某字符串的文件_beijihukk的博客-CSDN博客_find 查找字符串 ---- mac 也适用 安宇雨 打字音 记录集合 B站 bilibili 自行搭建 开坑 真正的客制化 安宇雨 黑苹果开坑 查找工具包maven pom 引用地 工具网站 Dantelis 介绍的玩轴入坑攻略 --- 关于轴的一些说法 --- 非官方 ---- 心得而已 --- 长期开坑更新 [本人问题][新开坑位]关于自动化测试的工具与平台应用 机械键盘 开团 网站记录 -- 能做一个收集的程序就好了 不过现在没时间 -- 信息大多是在群里发的 - 你要让垃圾佬 都去一个地方看难度也是很大的 精神支柱 [超级前台]sprinbboot maven superdesk-app 记录 [信息有用] [环境准备] [基本完成] [sebp/elk] 给已创建的Docker容器增加新的端口映射 - qq_30599553的博客 - CSDN博客 [正在研究] Elasticsearch, Logstash, Kibana (ELK) Docker image documentation elasticsearch centos 安装记录 及 启动手记 正式服务器 39 elasticsearch 问题合集 不断更新 6.1.1 | 6.5.1 两个版本 博客程序 - 测试 - bug记录 等等问题 laravel的启动过程解析 - lpfuture - 博客园 OAuth2 Server PHP 用 Laravel 搭建带 OAuth2 验证的 RESTful 服务 | Laravel China 社区 - 高品质的 Laravel 和 PHP 开发者社区 利用Laravel 搭建oauth2 API接口 附 Unauthenticated 解决办法 - 煮茶的博客 - SegmentFault 思否 使用 OAuth2-Server-php 搭建 OAuth2 Server - 午时的海 - 博客园 基于PHP构建OAuth 2.0 服务端 认证平台 - Endv - 博客园 Laravel 的 Artisan 命令行工具 Laravel 的文件系统和云存储功能集成 浅谈Chromium中的设计模式--终--Observer模式 浅谈Chromium中的设计模式--二--pre/post和Delegate模式 浅谈Chromium中的设计模式--一--Chromium中模块分层和进程模型 DeepMind 4 Hacking Yourself README.md update 20211011
友情链接
Laravel China 简书 知乎 博客园 CSDN博客 开源中国 Go Further Ryan是菜鸟 | LNMP技术栈笔记 云栖社区-阿里云 Netflix技术博客 Techie Delight Linkedin技术博客 Dropbox技术博客 Facebook技术博客 淘宝中间件团队 美团技术博客 360技术博客 古巷博客 - 一个专注于分享的不正常博客 软件测试知识传播 - 测试窝 有赞技术团队 阮一峰 语雀 静觅丨崔庆才的个人博客 软件测试从业者综合能力提升 - isTester IBM Java 开发 使用开放 Java 生态系统开发现代应用程序 pengdai 一个强大的博主 HTML5资源教程 | 分享HTML5开发资源和开发教程 蘑菇博客 - 专注于技术分享的博客平台 个人博客-leapMie 流星007 CSDN博客 - 舍其小伙伴 稀土掘金 Go 技术论坛 | Golang / Go 语言中国知识社区


最新评论