达观推荐算法实现:协同过滤之item embedding - 51CTO.COM
- 安宇雨 - 随手采集
- 2019-04-12 01:14:50
- 随手采集
- 0000-未整理-等待研究
推荐系统本质是在用户需求不明确的情况下,解决信息过载的问题,联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展现在对它感兴趣的用户面前,从而实现信息消费者和信息生产者的双赢(这里的信息的含义可以非常广泛,比如咨询、电影和商品等,下文中统称为item)。达观数据相关推荐是达观推荐系统中的重要组成部分,其价值在于,在没有用户画像信息的情况下,也能给用户以好的推荐体验,比如资讯类,通过达观相关推荐算法找到item相关的其他item,可以提供对某一类或者针对某一事件多角度多侧面的深度阅读。本文主要先简单介绍相关推荐的一些常用算法,然后介绍一下基于item embedding的协同过滤。

1. 达观相关推荐的常用算法
1.1 Content-based相关推荐
基于内容的推荐一般依赖于一套好的标签系统,通过计算item之间tag集合的相似性来衡量item之间的相似性,一套好的标签系统需要各方面的打磨,一方面需要好的编辑,一方面也依赖于产品的设计,引导用户在使用产品的过程中,对item提供优质的tag。
1.2 基于协同过滤的相关推荐
协同过滤主要分为基于领域以及基于隐语义模型。
基于领域的算法中,ItemCF是目前业界应用最多的算法,其主要思想为“喜欢item A的用户大都喜欢用户 item B”,通过挖掘用户历史的操作日志,利用群体智慧,生成item的候选推荐列表。主要统计2个item的共现频率,加以时间的考量,以及热门用户以及热门item的过滤以及降权。
LFM(latent factor model)隐语义模型是最近几年推荐系统领域最为热门的研究话题,该算法最早在文本挖掘领域被提出,用于找到文本隐含的语义,在推荐领域中,其核心思想是通过隐含特征联系用户和物品的兴趣。主要的算法有pLSA、LDA、matrix factorization(SVD,SVD++)等,这些技术和方法在本质上是相通的,以LFM为例,通过如下公式计算用户u对物品i的兴趣:
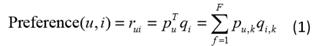
公式中pu,k和qi,k是模型的参数,其中pu,k度量了用户u的兴趣和第k个隐类的关系,而qi,k度量了第k个隐类和物品i之间的关系。而其中的qi,k可视为将item投射到隐类组成的空间中去,item的相似度也由此转换为在隐空间中的距离。
2. item2vec:NEURAL ITEM EMBEDDING
2.1 word2vec
2013年中,Google发布的word2vec工具引起了大家的热捧,很多互联网公司跟进,产出了不少成果。16年Oren Barkan以及Noam Koenigstein借鉴word2vec的思想,提出item2vec,通过浅层的神经网络结合SGNS(skip-gram with negative sampling)训练之后,将item映射到固定维度的向量空间中,通过向量的运算来衡量item之间的相似性。下面对item2vec的做简要的分享:
由于item2vec基本上是参照了google的word2vec方法,应用到推荐场景中的item2item相似度计算上,所以首先简单介绍word2vec的基本原理。
Word2vec主要用于挖掘词的向量表示,向量中的数值能够建模一个词在句子中,和上下文信息之间的关系,主要包括2个模型:CBOW(continuous bag-of-word)和SG(skip-gram),从一个简单版本的CBOW模型介绍,上下文只考虑一个词的情形,如图1所示,
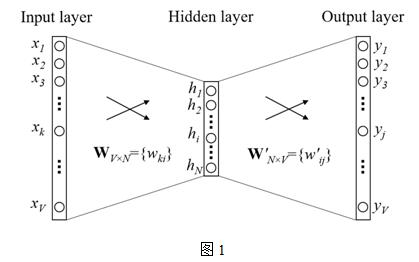
假设只有一个隐层的神经网络,输入层以及输出层均为词的one-hot编码表示,词表大小假设为V,隐层神经元个数为N,相邻层的神经元为全连接,层间的权重用V*N的矩阵W表示,隐层到输出层的activation function采用softmax函数,
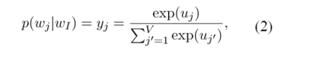
其中wI,wj为词表中不同的词,yj为输出层第j个神经元的输出,uj为输入层经过权重矩阵W到隐层的score,uj’为隐层经过权重矩阵W’到输出层的score。训练这个神经网络,用反向传播算法,先计算网络输出和真实值的差,然后用梯度下降反向更新层间的权重矩阵,得到更新公式:
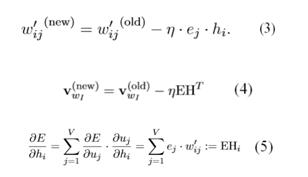
其中,η为更新的步长,ej为模型预测以及真实值之间的误差,h为隐层向量。
图2为上下文为多个词时的情况,中间的隐层h计算由
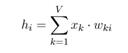
改为
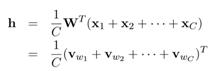
即输入向量为多个上下文向量相加求平均,后续的参数学习与上文的单个词的上下文情况类似。遍历整个训练集context-target词对,经过多次迭代更新模型参数,对模型中的向量的影响将会累积,最终学到对词的向量表示。
Skip-gram跟CBOW的输入层和输出层正好对调,区别就是CBOW是上下文,经过模型预测当前词,而skip-gram是通过当前词来预测上下文。
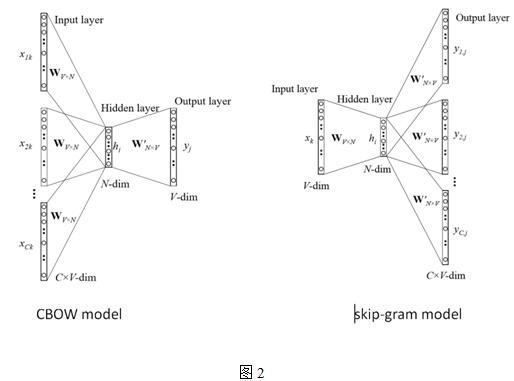
目前为止,对词表中的每个词,有两种向量表示:input vector和output vector,对应输入层到隐层权重矩阵W的行向量和隐层到输出层权重矩阵W'的列向量,从等式4、5可以看出,对每一个训练样本,都需要遍历词表中的每一个词,因此,学习output vector的计算量是非常大的,如果训练集或者词表的规模大的话,在实际应用中训练不具可操作性。为解决这个问题,直觉的做法是限制每个训练样本需要更新的output vectors,google提出了两个方法:hierarchical softmax和negative sampling,加快了模型训练的速度,再次不做展开讨论。
2.2 item2vec
由于wordvec在NLP领域的巨大成功,Oren Barkan and Noam Koenigstein受此启发,利用item-based CF学习item在低维latent space的embedding representation,优化item的相关推荐。
词的上下文即为邻近词的序列,很容易想到,词的序列其实等价于一系列连续操作的item序列,因此,训练语料只需将句子改为连续操作的item序列即可,item间的共现为正样本,并按照item的频率分布进行负样本采样。
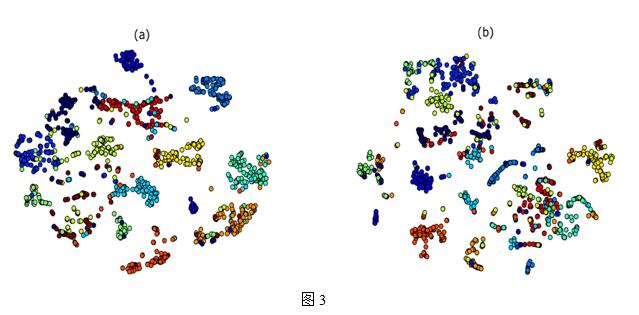
Oren Barkan and Noam Koenigstein以SVD作为baseline,SVD的隐类以及item2vec的维度都取40,用Microsoft Xbox Music service收集的 user-artists数据集,对结果进行聚类,如图3所示,图a是item2vec的聚合效果,图b是SVD分解的聚合效果,看起来item2vec的聚合效果要更好些。
作者尝试将item2vec应用到达观数据的相关推荐当中,由于资讯、短视频类的场景一般的连续item操作会比较多,因此天然的非常适合用item2vec来训练item的向量表示,从实际的训练结果和线上评估来看,item2vec对CTR提升是有明显帮助的。
本文作者:
范雄雄,达观数据个性化推荐引擎工程师,工作包括推荐系统的架构设计和开发、推荐效果优化等,所在团队开发的个性化推荐系统曾创造上线后效果提升300%的记录。复旦大学计算机科学与技术专业硕士,曾在爱奇艺开发多款大数据产品,对个性化推荐、数据挖掘和分析、用户行为建模、大数据处理有较深入的理解和实践经验。
【本文为51CTO专栏作者“达观数据”的原创稿件,转载可通过51CTO专栏获取联系】
【编辑推荐】
【责任编辑:武晓燕 TEL:(010)68476606】
原网址: 访问
创建于: 2019-04-12 01:14:50
目录: default
标签: 无
未标明原创文章均为采集,版权归作者所有,转载无需和我联系,请注明原出处,南摩阿彌陀佛,知识,不只知道,要得到
加入组织
-
-
1. 手Q扫左侧二维码
2. 搜Q群:861085013
3. 点击


热门标签
- Laravel (35)
- Elasticsearch (20)
- PHP (25)
- Mysql (15)
- centos (46)
- vue.js (7)
- javascript (1)
- node.js (5)
- python (1)
- git (13)
- gitlab (4)
- redis (3)
- nginx (7)
- sublime-text (1)
- bootstrap (1)
- 自然语言处理 NLP (2)
- 数据挖掘 (2)
- 机器学习 (5)
- 深度学习 (3)
- composer (7)
- Java!弃! (24)
- 超位魔法-Bug (1)
- 0000-未整理-等待研究 (7915)
- 微服务架构 (2)
- 创业 (3)
- 研发管理 (3)
- 绩效考核 (3)
- 人工智能 (3)
- Robot (1)
- 高等数学 (2)
- 思想想法-Mind (4)
- oAuth (9)
- CSS (5)
- C (5)
- MacOS (16)
- ES6 (19)
- Linux (17)
- Ubuntu (4)
- Kali (2)
- nvidia (1)
- BeyondCompare - 文件比对 (4)
- VMware (3)
- 0005-亲测可用 (48)
- 救援模式 (3)
- 0003-全部整理 - 已整理 (24)
- 0004-划重点-定要细看-Review (26)
- DevOps (1)
- kafka (1)
- svn (2)
- 南摩阿彌陀佛 (2)
- 阿里云 (1)
- gogs (6)
- oneinstack (6)
- PHP-环境 (1)
- 开源项目库介绍 (1)
- 敏捷开发 (2)
- Scrum (2)
- Laravel-迁移 (2)
- 数据丢失 (1)
- 转义 (3)
- Let's Encrypt (4)
- SSL (3)
- HTTPS证书 (4)
- Certbot (1)
- maven (16)
- nexus (15)
- Spring Boot (12)
- Spring Cloud (2)
- Spring (4)
- PDMan (2)
- AppImage (2)
- Docker (21)
- MyBatis (11)
- Generator (2)
- superdesk-libs (1)
- Homebrew (6)
- 热部署 (3)
- 操作系统 (1)
- 个人标记 (2)
- IDE (11)
- idea (10)
- 开发环境-搭建 (3)
- websocket (1)
- 专题-k8s-docker-springcloud-springboot (20)
- jQuery插件 (1)
- iptables (2)
- 专题-正则表达式 (2)
- Regex (2)
- 程序猿道具 (2)
- 撸代码道具 (2)
- 专题-elasticsearch-logstash-kibana (17)
- 专题-nginx-配置静态文件访问 (3)
- http.postbuffer (3)
- git-error (3)
- 墙外 (7)
- 0001-整理部分 - 研究ing (17)
- golang (2)
- utf8mb4 (2)
- golang镜像代理 (1)
- 机械键盘 (7)
- 机械键盘-客制化 (4)
- 机械键盘-商品类 (3)
- 机械键盘-改装 (18)
- 机械键盘-客制化配件 (4)
- 超级前台时期 (10)
- question-mysql (5)
- developer-龙美珍 (2)
- 机械键盘-本人制作 (8)
- linux-输入法-Input Method (6)
- fcitx (5)
- 营销广告 (2)
- Visual Studio Code (1)
- linux-command (2)
- ftp 工具 (2)
- FileZilla (2)
- ibus (1)
- 前端视觉 (3)
- JavaScript 3D library (2)
- 机械键盘-拆解评测 (9)
- 机械键盘-知识科普 (8)
- 机械键盘-维修 (2)
- 前端技术 (3)
- html5 (2)
- SEO (2)
- Sass (1)
- logback (2)
- Java-日志-框架 (4)
- 在线工具 (6)
- 自动化测试开坑 (4)
- Jmeter (3)
- 清除 history (3)
- 编程 - 可视化-道具 (1)
- superdesk-app-transfer (1)
- superdesk-app-transfer-old2new (1)
- superdesk-app-transfer-canal (2)
- superdesk-app-transfer-canal-instance-supercloud (1)
- superdesk-app-platform (2)
- superdesk-app-services (1)
- superdesk-app-services-common (1)
- 专题-Lambda (4)
- phpMyAdmin (7)
- 微擎 (1)
- 范型 (2)
- Java 不得不学 (2)
- 切面式编程(interceptor)(拦截器?) (2)
- 事件式编程(event) (3)
- TDD式编程 (1)
- Lombok (3)
- markdown - 解析器 (2)
- centos8 - 踩点 (2)
- 超级思维 (1)
- 个人发展协会 (2)
- Shadowsocks (6)
- 专题-spring cloud 全家桶 (1)
- brew (1)
- okhttp3 (1)
- 超级前台 (1)
- superdesk-uniorder (1)
- HHKB Professional BT蓝牙 (1)
- 电商军规:打造线上赚钱旺铺 (2)
- Swagger (1)
- Freemarker (1)
- 1011-收集箱 (1)
- 1015-专题研究 (1)
- 油猴 tampermonkey (1)
- 内网穿透 (4)
- 黑苹果 (1)
- Chrome 扩展 (2)
- Chrome Extension (2)
- 游戏 (1)
- 原神 3.0 须弥 (1)
- poi v3.16 (10)
- 分布式锁 (3)
- KiCad-7 (1)
- KiCad (11)
- APITable (4)
- 机器视觉 (9)
- VisionMaster (9)
- RXTXcomm (1)
- Purejavacomm (1)
- javaxcomm (2)
- 串口-RS232-RS485-Java (4)
置顶推荐
java windows火焰图_mob64ca12ec8020的技术博客_51CTO博客 - 在windows下不可行,不知道作者是怎样搞的 监听SpringBoot 服务启动成功事件并打印信息_监听springboot启动完毕-CSDN博客 SpringBoot中就绪探针和存活探针_management.endpoint.health.probes.enabled-CSDN博客 u2u转换板 - 嘉立创EDA开源硬件平台 Spring Boot 项目的轻量级 HTTP 客户端 retrofit 框架,快来试试它!_Java精选-CSDN博客 手把手教你打造一套最牛的知识笔记管理系统! - 知乎 - 想法有重合-理论可参考 安宇雨 闲鱼 机械键盘 客制化 开贴记录 文本 linux 使用find命令查找包含某字符串的文件_beijihukk的博客-CSDN博客_find 查找字符串 ---- mac 也适用 安宇雨 打字音 记录集合 B站 bilibili 自行搭建 开坑 真正的客制化 安宇雨 黑苹果开坑 查找工具包maven pom 引用地 工具网站 Dantelis 介绍的玩轴入坑攻略 --- 关于轴的一些说法 --- 非官方 ---- 心得而已 --- 长期开坑更新 [本人问题][新开坑位]关于自动化测试的工具与平台应用 机械键盘 开团 网站记录 -- 能做一个收集的程序就好了 不过现在没时间 -- 信息大多是在群里发的 - 你要让垃圾佬 都去一个地方看难度也是很大的 精神支柱 [超级前台]sprinbboot maven superdesk-app 记录 [信息有用] [环境准备] [基本完成] [sebp/elk] 给已创建的Docker容器增加新的端口映射 - qq_30599553的博客 - CSDN博客 [正在研究] Elasticsearch, Logstash, Kibana (ELK) Docker image documentation elasticsearch centos 安装记录 及 启动手记 正式服务器 39 elasticsearch 问题合集 不断更新 6.1.1 | 6.5.1 两个版本 博客程序 - 测试 - bug记录 等等问题 laravel的启动过程解析 - lpfuture - 博客园 OAuth2 Server PHP 用 Laravel 搭建带 OAuth2 验证的 RESTful 服务 | Laravel China 社区 - 高品质的 Laravel 和 PHP 开发者社区 利用Laravel 搭建oauth2 API接口 附 Unauthenticated 解决办法 - 煮茶的博客 - SegmentFault 思否 使用 OAuth2-Server-php 搭建 OAuth2 Server - 午时的海 - 博客园 基于PHP构建OAuth 2.0 服务端 认证平台 - Endv - 博客园 Laravel 的 Artisan 命令行工具 Laravel 的文件系统和云存储功能集成 浅谈Chromium中的设计模式--终--Observer模式 浅谈Chromium中的设计模式--二--pre/post和Delegate模式 浅谈Chromium中的设计模式--一--Chromium中模块分层和进程模型 DeepMind 4 Hacking Yourself README.md update 20211011
友情链接
Laravel China 简书 知乎 博客园 CSDN博客 开源中国 Go Further Ryan是菜鸟 | LNMP技术栈笔记 云栖社区-阿里云 Netflix技术博客 Techie Delight Linkedin技术博客 Dropbox技术博客 Facebook技术博客 淘宝中间件团队 美团技术博客 360技术博客 古巷博客 - 一个专注于分享的不正常博客 软件测试知识传播 - 测试窝 有赞技术团队 阮一峰 语雀 静觅丨崔庆才的个人博客 软件测试从业者综合能力提升 - isTester IBM Java 开发 使用开放 Java 生态系统开发现代应用程序 pengdai 一个强大的博主 HTML5资源教程 | 分享HTML5开发资源和开发教程 蘑菇博客 - 专注于技术分享的博客平台 个人博客-leapMie 流星007 CSDN博客 - 舍其小伙伴 稀土掘金 Go 技术论坛 | Golang / Go 语言中国知识社区


最新评论